

type
Post
status
Published
date
Nov 8, 2023
slug
open-ocr-effocr
summary
EffOCR 使用了切字+向量检索的方法来做文字识别,很不一样的思路,非常有趣。
tags
模型下载
OCR
EffOCR
CnOCR
英文OCR
日文OCR
切字
对比学习
度量学习
文字检测
文字识别
category
开源工具
icon
password
URL
Rating
.jpeg?table=block&id=359b19c3-1ed0-4bf5-b915-e27882d95cf0&t=359b19c3-1ed0-4bf5-b915-e27882d95cf0&width=1024&cache=v2)
EffOCR:Efficient OCR 的简写。EffOCR 使用了一种让我既意外又惊喜的方式来解决文字识别问题,是我近两年来见过的最好玩的OCR方案。按照作者的实验,EffOCR 不仅精度达到甚至超过了SOTA,而且识别速度还提升了
50%以上。But, …
EffOCR 主要针对的是旧的印刷物的电子化问题,尤其是针对那些资源比较少的文字。但 EffOCR 也完全可以应用于场景文字识别问题。

<ins/>
思路介绍
当前主流的 OCR 引擎,流程是先用文字检测器检测出单行文字,然后把单行文字对应的图片patch编码为序列向量,再建模为序列标注任务(如 CRNN),或者生成任务(如 Transformer),最终识别出整行文字,如下图底部流程。关于主流的 OCR 引擎(如 CnOCR)的更详细说明,可见我之前的分享:文本检测和识别——附CnStd与CnOcr工具介绍。
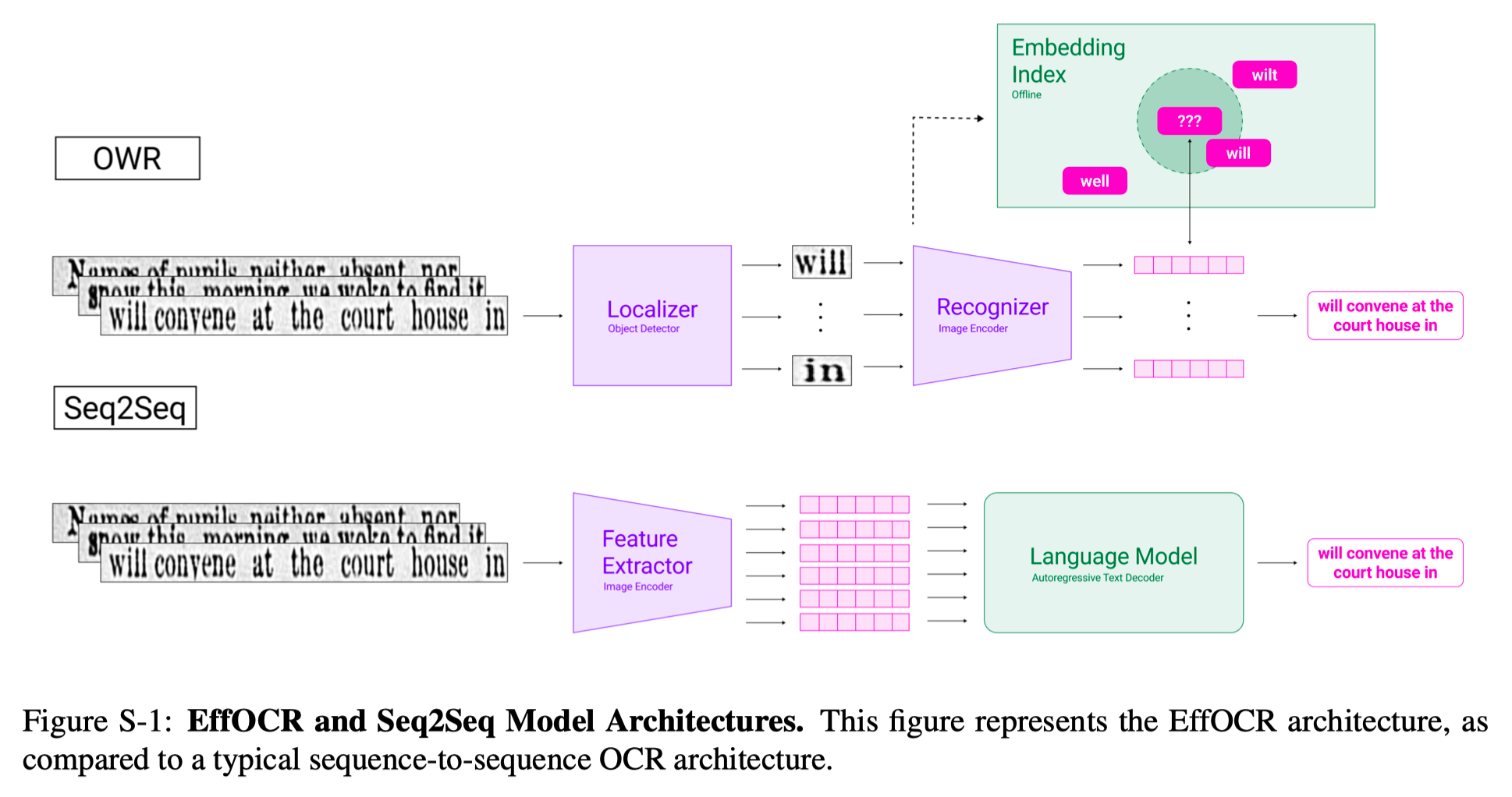
而 EffOCR 使用了完全不同的方法。
EffOCR 和传统方法一样,通过文字检测模型获取到单行文字patch的图片。EffOCR 中称这个模型为
line_detector 或者 LineModel。之后,EffOCR 对单行文字图片先做切字(英文里可以是词),然后计算每个切好字的图片的编码向量,并在所有可能候选字符集对应的编码向量中检索最接近的字。检索出所有切字对应的最相似字符,拼接在一起后就得到识别结果。流程如上图顶部。
EffOCR 中的切字使用了目标检测模型,如 Yolo 系列,通过检测出所有单个字符(或词)来做切字分割。EffOCR 中称这个模型为
localizer_model 或者 LocalizerModel。把切完的字的图片编码为向量的编码模型,是通过对比学习(度量学习)训练得到的,大致思路就是让同一个字在不同字体,不同背景下的图片的编码向量尽可能接近,不同字的编码向量近可能远离。对比学习相关的知识可以参考我之前的一些分享,如:

EffOCR 中称这类模型为
Recognizer。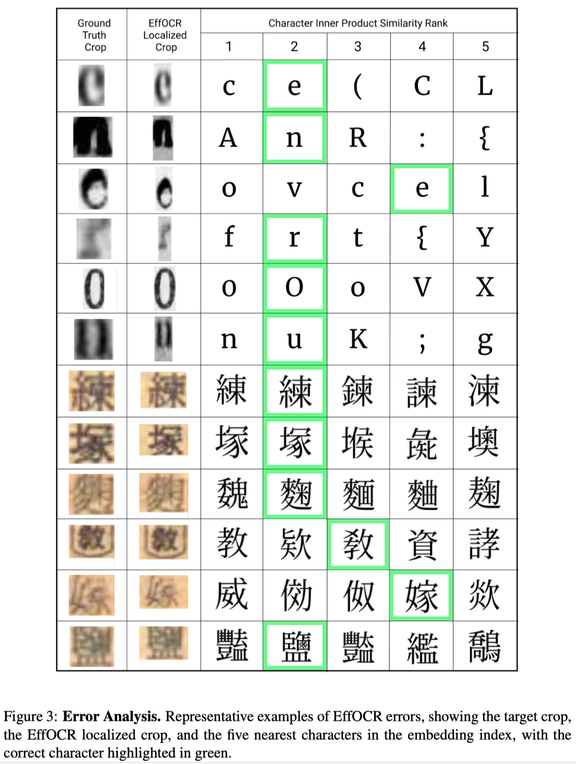
所以可以说,
EffOCR = 切字 + 向量检索
切字这个思路其实是最早期做文字识别的一种思路,只是当时一般利用图片的像素直方图来找到切分点,这种方法只要背景稍微复杂一点或者字间距较小都很容易失败。
有了序列模型后就很少有人再用先切字再识别的方法了。没想到 EffOCR 利用目标检测方法来完成切字,看似“外行”的方法却取得了非常不错的精度。
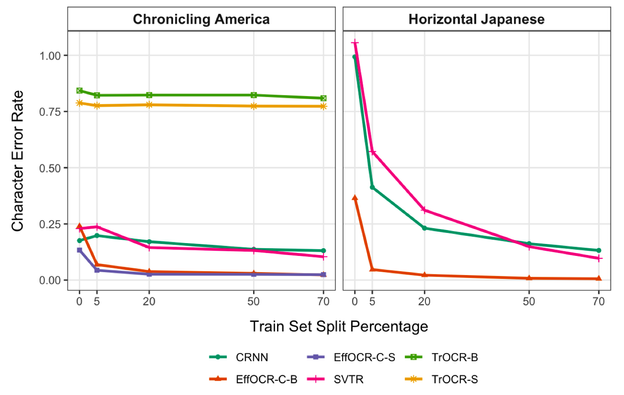
精度比较
作者的实验结果是 EffOCR 能达到 SOTA 的识别精度。
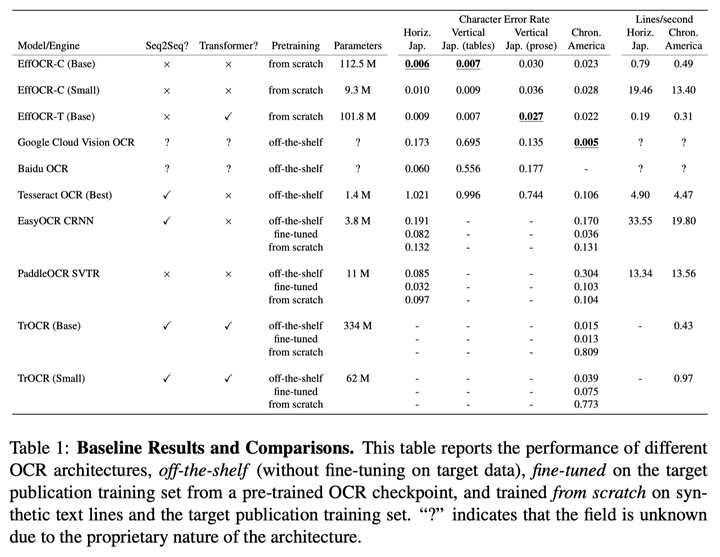
速度比较
因为不使用序列模型架构,EffOCR 在识别时能有更快的速度。
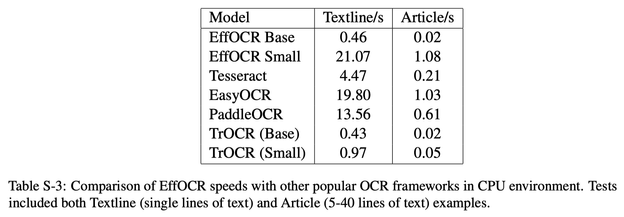
少样本精调模型
对于新的字符集,相比于其他架构的识别模型,EffOCR 能在更少的数据上精调出效果不错的模型。
这种对比其实是不太公平的。其他架构预测的是序列,EffOCR 本质识别的是单字。
效果尝试
我很努力地想跑通作者的代码,看看在具体图片上的效果。可惜失败了。
首先,官方Github库 压根就没有能直接跑的脚本,代码那个乱。。
论文中虽然说他们训练了很多模型,支持英文和日文(不支持中文)。但我在 他们的HuggingFace页面 只找到了英文模型的下载地址。
但识别时报以下错误,应该是模型支持的输入图片是
224 x 224 的,但默认代码又把图片resize成 640 x 640 的了。虽然我手动把图片再resize成 224 x 224 后不会报错,但什么东西都识别不出来😅。。所以最终我还是没有复现出效果😭 ,不过 EffOCR 的思路还是很有意思的,值得学习和借鉴。
优缺点
既然要切字,那就得保证字与字之间有间距。一旦字与字有重叠现象(如手写体)那切字不仅很难切好,就算切好了单字图片上还会包含临近字的笔画,可能会严重影响检索精度。所以作者是在印刷品的电子化场景下使用的 EffOCR。
但有些应用场景不仅希望识别出最终文字,还希望返回每个字的位置坐标,以及每个字的识别分数。这种场景就很适合使用 EffOCR 的思路。
以下对当前 OCR 的三种主流框架做个粗略的比较,欢迎不同意见:
ㅤ | EffOCR:切字+向量检索 | 传统OCR方法 | 端到端生成式:ViT |
训练消耗 | 小 | 中 | 大~超大 |
推断消耗 | 中 | 中 | 大 |
精调消耗 | 小 | 中 | 大 |
精度 | 中 | 中 | 中~优 |
速度 | 快~更快 | 快 | 慢 |
识别 | 单字 | 一行字的序列 | 整段字的序列 |
适用场景范围 | 小 | 中 | 大 |
<ins/>
Resources
- Home: Efficient OCR


- 英文模型下载:dell-research-harvard/effocr_en · Hugging Face,日文的模型没找到下载地址
- 作者:Breezedeus
- 链接:https://www.breezedeus.com/en/article/open-ocr-effocr
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章












