

type
Post
status
Published
date
Sep 24, 2016
slug
chatbot-tradeoff
summary
本文探讨了对话交互作为人机交互最高效方式的必然性,并分析了不同 bot 平台在可控性与智能性之间权衡的特点,认为技术进步将不断扩大这一权衡边界。
tags
Chatbot
对话机器人
聊天机器人
Dialogue
可控性
智能性
yige.ai
wit.ai
viv
api.ai
Bot-Maker
category
技术分享
icon
password
URL
Rating

本文很长,但其实我只分享以下两个个人观点,欢迎大家指正:
- 对话交互会在 IoT 万物互联时代爆发,这是追逐交互效率的必然结果。
- 不同的 bot 和 bot 平台的差别其实只是在可控性和智能性之间的权衡不同。技术的发展只是在不断拓展可控性和智能性的帕累托边界而已。
对话交互将是人与机器最高效的交互方式
交互,就是不同物体进行信息交换的过程。信息交换效率是衡量交互最重要的指标。人与机器的交互,将追随人与人交互的演化路径。
<ins/>
人与人的交互
在语言发明前,人类的祖先智人主要是通过什么方式进行交流的?一种方式是用肢体做动作,模仿各种活动,比如动物;另一种方式则是喊叫,通过不同的喊叫声来传达一些简单信息,比如危险靠近、找到食物。大部分其他动物的交流方式到现在也是如此。第一种交流方式对应的就是图形交互,用到的器官主要是眼睛,其主要约束来自于空间:距离不能太远,不能移动太快,不能被东西遮挡等。第二种交流方式对应的则是对话交互,用到的器官主要是耳朵,其对空间的依赖性更低:距离可以很远,移动和遮挡影响也不大。
在发明语言后,人类进一步提高了第二种交流方式(对话交互)的效率和信道容量。对话交互碾压图形交互成为人与人最重要的交流方式。使用对话交互,人类可以同时与多人进行较远距离的实时交流。相比于图形(眼睛),现在人类对语音(耳朵)的并行处理能力要强得多。这可能就是进化的结果。
人类也一直在努力改进对话交互方式。通过电话我们已经可以和地球任一个角落的其他人进行交流,前提是对方得在电话旁边。对方老不在怎么办?让他一直把电话带身旁(手机)。什么,你想交互更便捷、便宜,对话交互时还能融合图形交互?微信吧。
最后总结下人类交流方式的发展路径,基本就是在不断改善对话交互的效率,降低空间和时间对它的约束:
- 语言发明前:主要使用图形交互方式,受空间和时间约束巨大;
- 语言发明后:主要使用对话交互方式,受空间和时间约束变小,但仍然很大;
- 电话和手机发明后:极大改善了对话交互方式,不再受空间约束,但时间约束仍较大;
- (移动)互联网发明后:人类几乎一直在线,对话交互方式基本不再受时间的约束。
人与机器的交互
在计算机刚被发明时,计算机可以被认为是一种很低等的物种。人类作为高级物种在跟低级物种计算机进行交流时,必须迁就计算机,使用它喜欢的语言(汇编、命令行)。这就像主流文明社会如果要跟深山里的原始部落进行交流,开始阶段只能是文明社会去学习原始部落的交流方式然后与他们交流。随着计算机逐渐被动进化出外表(图形),人类逐渐学会了与它通过图形交互进行交流,并在发展过程中逐渐提升交流效率(PC、APP早期时代)。
文明社会学会了原始部落的语言后,会反过来再教导原始部落学习文明社会的语言,因为文明社会所使用的语言表达能力更强,效率更高。人类与计算机的交互进化路径也会如此,因为最终目的都是人类获得交互效率的提升。为什么要计算机迁就人类?因为人类进化太慢。人类在经过长达百万年的进化后,对话交互已成为人类目前可接受的最高效沟通方式。显然我们没法为了提升与计算机的交互效率短时间让自己再进化进化,所以只能让计算机进化出人类最喜欢的对话沟通能力。这就是为什么人类一直不遗余力地发展计算机的(语音)对话交互能力。
人机交互接下来的发展路径会和人人交互的发展路径相同——人类会让机器一直保持在线。这不就是IoT时代的目标么。随着IoT万物互联时代的临近,人类需要与各种机器进行交互。相比于图形交互,对话交互具有更好的迁移性。使用图形交互,与不同的机器沟通就要开发不同的图形交互界面(想想PC和手机的图形交互差别有多大),但我们却可以跟所有东西使用相同的对话沟通方式。
让所有机器都具有对话交互能力,人类就可以并行地与多台机器同时进行交互。(想想钢铁侠里男主角在工作室工作的情景吧。)没有对话交互,那你让你家吸尘器工作时还得深情地看着它。。。
当然,以后人类可能会发展出更高效的人机、人人交互方式,比如直接用脑电波进行交互(想想三体人)。但这个目前看还是需要段时间的。在此之前,
对话交互是最高效的人人交互方式,也将成为最高效的人机交互方式。
<ins/>
各种对话交互(Bot)平台
首先需要承认,现在机器的智能还非常有限,它们没法和人类做到什么都能聊(开放域对话交互),但是在某些小的垂直领域它们已经能和人聊的很好(任务导向对话交互)。这种现状应该还会持续一段时间。现在大部分Bot领域的公司做的事都是与任务导向对话交互相关。
那怎么开发任务导向的对话机器人系统呢?如果你只是想让机器人用在一个固定领域或固定企业业务,那么你针对此领域或此企业业务进行技术优化即可。这时候使用的技术可以具有领域特性,不需要能够推广到其他领域或者其他业务。这里最有代表性的是Google的Gmail和Allo中的Smart Reply功能。
如果你的系统是帮助其他开发者更便捷地开发对话机器人,即Bot创建平台,那么使用的技术就最好不要与某个领域或业务有关。国外比较典型的是Facebook的Wit.ai和Google的Api.ai,国内也有不少创业公司在做这方面的事,比如一个AI、知麻、如意等,基本处于起步阶段。
篇幅有限,接下来我们只讨论第二类对话系统,即Bot创建平台,对Gmail和Allo的Smart Reply感兴趣的同学可以看看我之前写的Google的智能问答技术。
不同的Bot平台:可控性与智能性的权衡
企业通常会更关注自己bot的可控性,也即掌控力度,在出现问题时必须快速定位并解决。企业宁愿bot答不上来,也不能允许它瞎答。而用户当然希望bot能解答自己的各种问题,所以bot一定是越智能越好。但可控性和智能性本身就是一对互相矛盾的性质,智能本就包含了不可控。我一直记得K.K.在《失控》中的一个观点:智能来自于失控。
基于可控性和智能性的矛盾性,再考虑到现阶段技术的可行性,各种bot平台能做的就只能是在可控性和智能性之间找平衡点了。技术的发展只是会不断拓展可控性和智能性的帕累托边界而已。
下面介绍几类典型的bot平台:微信与旺旺、Viv、Api.ai与一个AI、Wit.ai,它们似乎大不相同,其实也只是在可控性和智能性之间的权衡不同罢了,见下图。一个bot平台想要获得更好的智能性,那它就要付出可控性的代价。(一个AI放在api.ai上面倒不是说现在它的智能性比api.ai强,而是表明我们对一个AI的定位,希望它能在中文方面做得比api.ai好。)把Gmail的Smart Reply功能放在图中的原因是把它作为其他bot平台的参照对象。作为特定领域的bot,它能够更好地兼顾可控性和智能性。
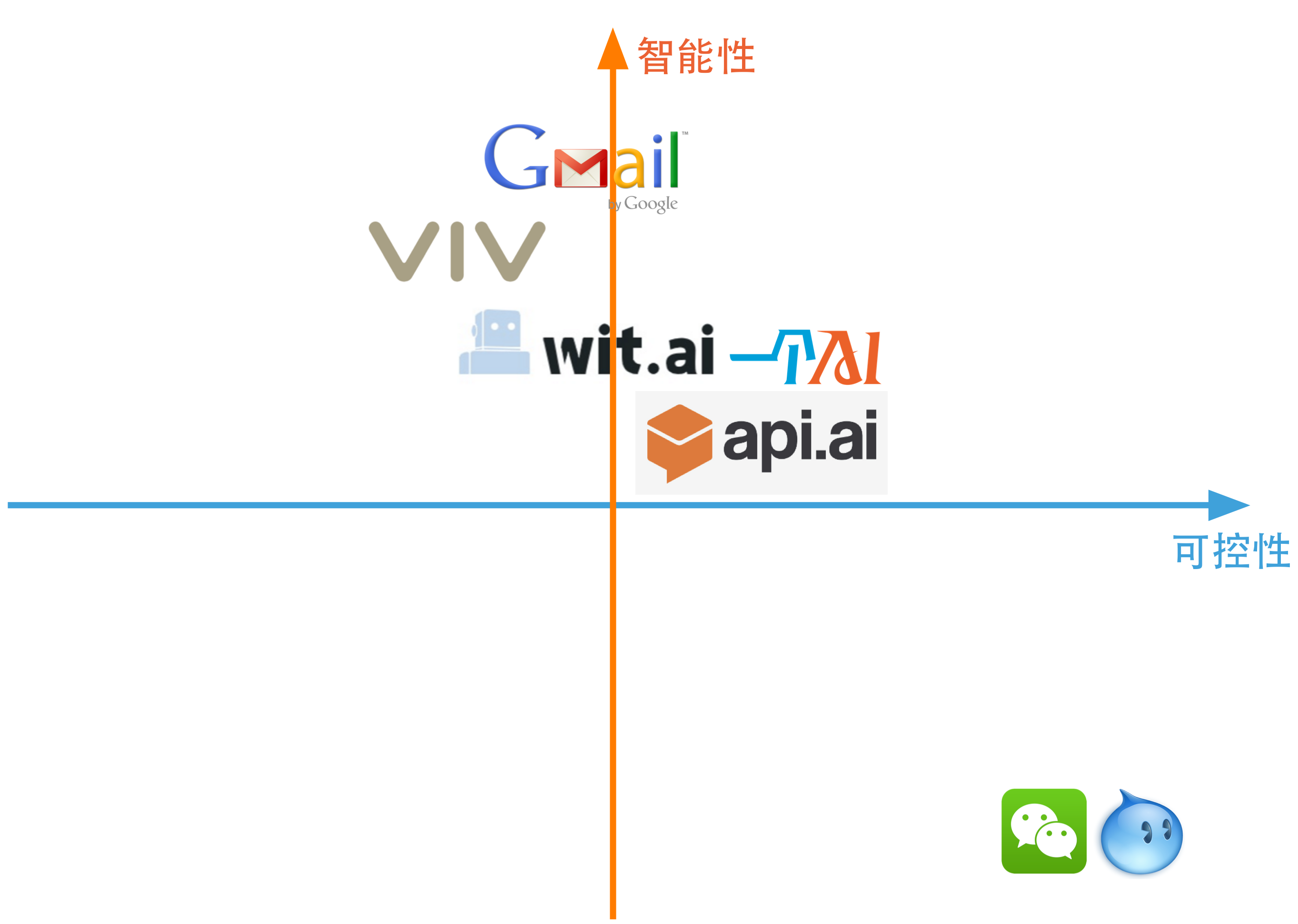
下面分别介绍这几类bot平台。
一、极度可控的微信和旺旺
其实我们早就在用各种bot服务了,这些bot太不智能以至于我们都没把它们往bot这个方向上想。比如各种电话服务里的操作步骤,旺旺里商家维护的常见问题列表,微信公众号里的菜单和功能编码:
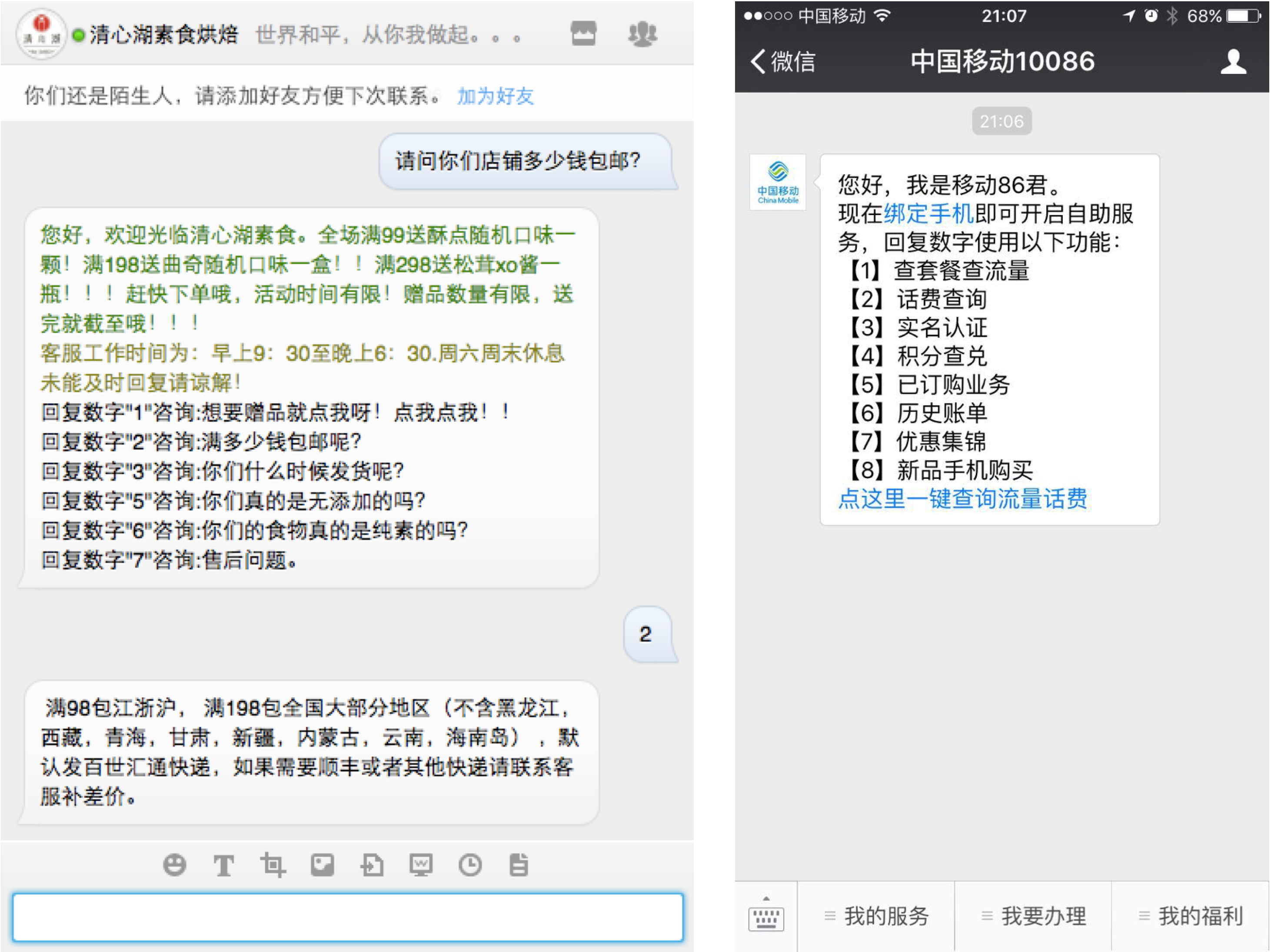
这些bot虽然不智能,但是却很有用,因为它们很可靠,不会犯错误。我们点击微信里的菜单,获得的响应一定是公众号管理者设定好的那个反馈,不会因为系统理解错而出现管理者不希望出现的东西。
二、较可控和较智能的 Api.ai 和 一个AI
Api.ai 目前应该是美国最流行的bot创建平台。9月19日,Api.ai宣布自己被Google收购。相比于Viv,api.ai的优势是简单和可控,它里面的每个意图通常只包含一轮对话,开发者只需要维护其中的用户提问、机器回复、动作,以及涉及到的实体。这样系统可以依据用户设定的这些数据训练模型以便在服务时预测用户输入对应的意图和识别包含的实体。
在接收到用户输入后,系统会分析用户的输入,预估用户的意图,以及识别输入中包含的实体,这些实体是在达成意图时需要的。下图给出了完成一次请求时的大致流程和一个示例。
Api.ai 好的可控性降低了开发者的使用和维护门槛,它的灵活性较Viv低但也能满足大部分应用的需求。但是,api.ai 对中文的支持很差,在国内访问延时也很大。前几天它宣布被Google收购了,估计被墙也只是时间问题。基于这些原因我们开发了 一个AI,希望通过一个AI把api.ai范式的强大和便捷带给国内开发者。下面详细介绍下 一个AI。
一个AI(www.yige.ai)是一个创建聊天机器人(bot)的免费在线平台。利用一个AI,开发者甚至产品和运营人员都可以轻松地开发聊天机器人应用,而不需要具备机器学习与自然语言处理等相关知识。一个AI的使命是:
让每个人都能轻松开发一个AI应用。

一个AI 中包含几个重要概念:词库、场景、动作、状态。词库是一个规范的自然语言短语集合,通常定义为应用所在领域的关键词、术语。词库在学术领域通常被称为实体(entity),是自然语言处理中的重要概念。词库在一个AI中用于从用户输入中提取动作和状态所需的参数值。一个AI不仅内置了常用的系统类型,如数字、日期、时间等,也为开发者定义自己词库提供了灵活便捷的支持。开发者可以定义包含同义词的同义词词库,也可以定义不包含同义词的枚举词库,甚至可以定义由其他词库组合而成的组合词库。
一个AI 中的场景通常对应着从用户提问到AI产生答复的一轮交互过程。一个场景主要由用户提问、AI回复、动作和输入输出状态所组成。
动作是用户提问匹配到的场景执行后触发的一个特定操作,它可以使用从用户输入中提取出的词库作为输入参数。动作相当于代码中的函数,其具体实现在开发者端,一个AI系统端只是一个标识,相当于函数声明。
状态记录了对话交互的背景信息,主要用于上下文信息(如参数值)的传递。此外,它也被用于管理会话流,串联起原本孤立的不同场景。多个场景通过场景里的输入输出状态连接成图网络以完成更加复杂的功能。
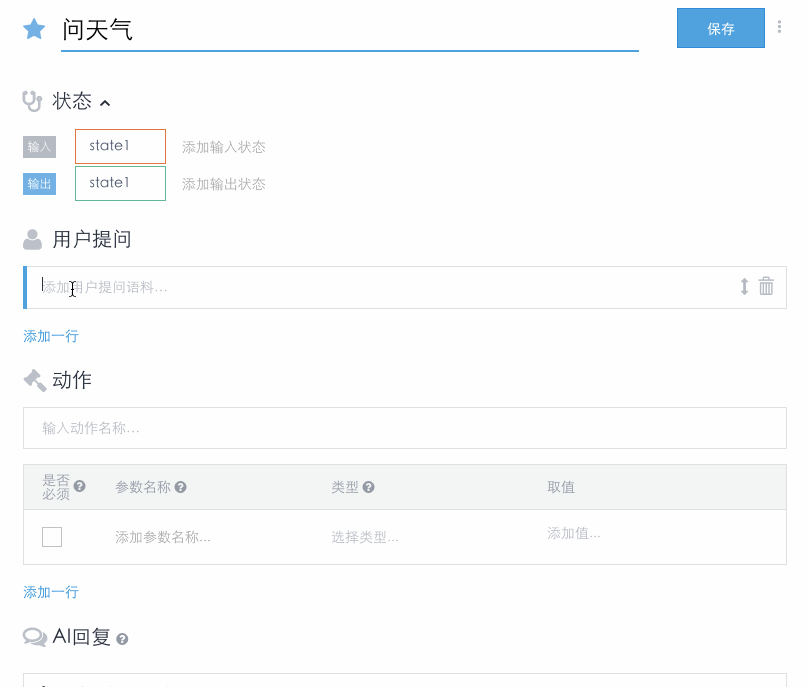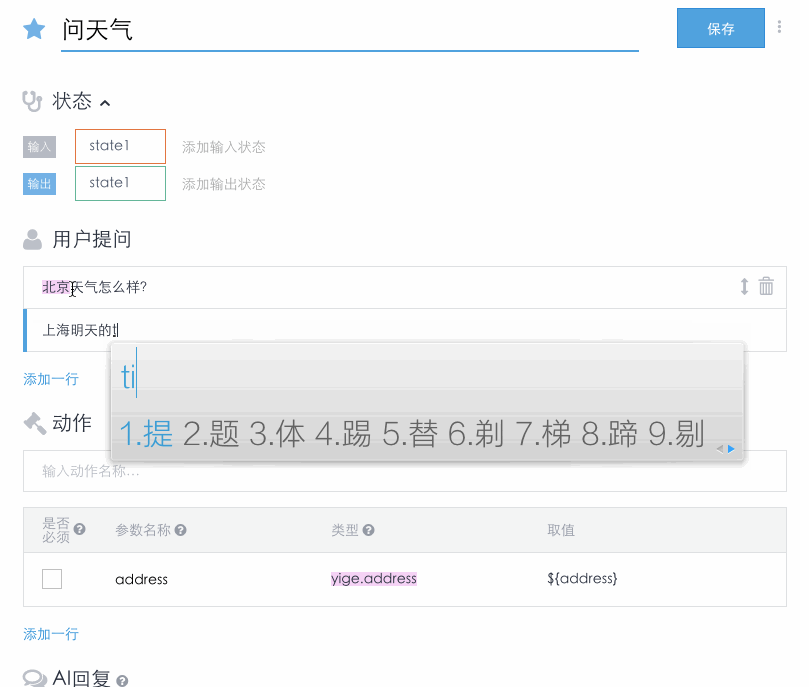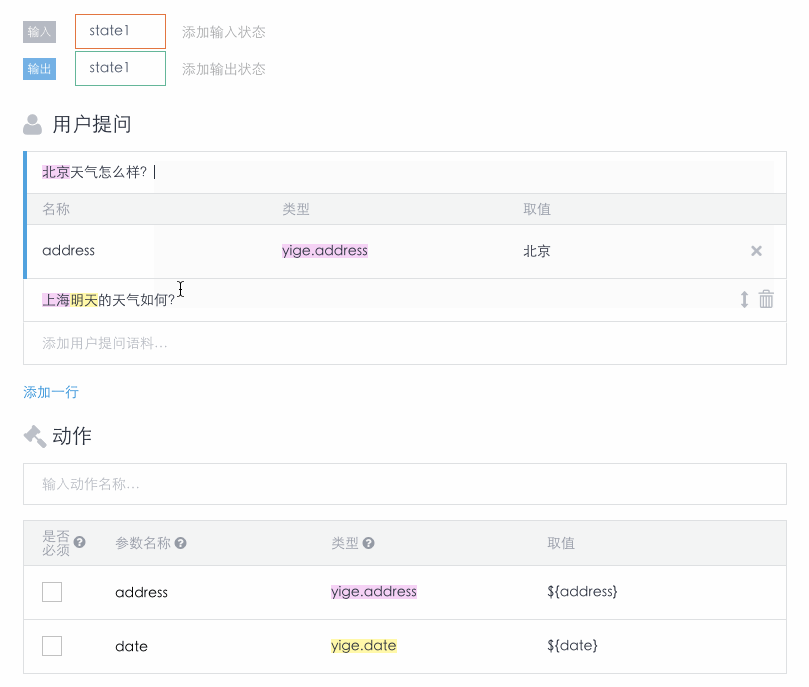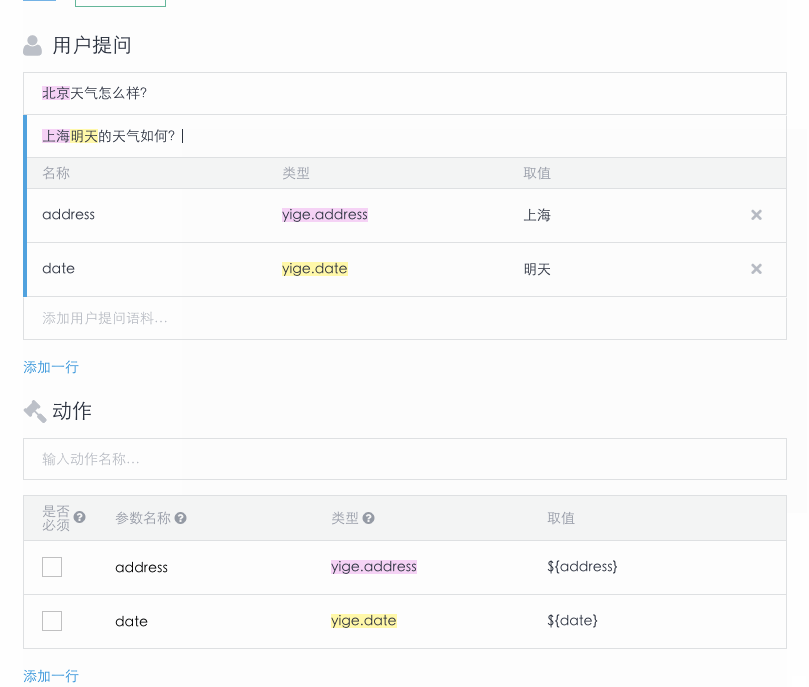
一个AI 遵循的流程和 Api.ai 类似(见之前的流程图)。在接收到用户的输入后,流程如下:
- 一个AI首先识别用户输入中的词库和用户场景。词库和场景的识别并不是独立的,相同的词在不同的场景下可能属于不同的词库类型。在场景识别时也会考虑到场景设定的状态是否存在。如果某场景设定的输入状态不是都存在,则不会把用户输入识别为此场景。
- 查看动作中需要的必须参数是否都已获得取值。如果存在必须参数还没有获得取值,就触发设定好的提示语作为机器人回复,要求用户输入对应的参数取值。参数的取值不仅可以来自于此次用户输入中的词库,也可以来自于输入状态中的变量。对于非必须参数,可以为他们设定默认值。
- 只有所有必须参数都已收集到取值,此场景才能完成,场景设定的AI回复才会作为回复返回给用户。到这里此场景就完成了,用户之后的输入就会触发新的循环。
一个AI定位于服务国内开发者,所以也引入了一些中文相关的特性,例如查询接口支持未分词的整句话输入,以及分词后的语句输入。
关于一个AI的由来,可见我之前的文章“创建Bot的中文平台——一个AI(yige.ai)”。更多信息可见一个AI官方文档,也欢迎大家去 一个AI官网(www.yige.ai)逛逛,尝试创建年轻人的第一个AI应用吧^_^。
<ins/>
三、更智能的 Viv
Viv 中主要包含了两种对象:概念对象(Concept Object)和动作对象(Action Object),其中概念对象指的就是实体,而动作对象就是执行的动作。以概念和动作对象为结点,Viv构建了规模庞大的有向网络图。概念结点到动作结点的边表示此动作以此概念为输入参数,而动作结点到概念结点的边表示此动作的输出中包含了此概念。如果两个概念结点存在扩展(“is a”)或者属性(“has a”)关系,那么它们之间也会存在有向边。随着开发者不断把新的概念和动作对象加入到Viv系统,这个网络图会逐渐延伸,越来越大。借助于Viv的动态演化认知架构系统(Dynamically Evolving Cognitive Architecture System,简称DECAS),Viv能做的事会随着网络图的增大而指数增长。
DECAS的核心,是如何串联起不同的动作来达成目标。放在之前提到的概念和动作组成的网络图里面说,其实就是找意图中概念结点到意图中目标结点的各种连通路径。(虽然 Viv 没有具体说,但目标结点应该也是一种概念结点。)Viv把一条路径称为一个计划(Plan)。计划中使用到的动作可以跨应用,可以来自于不同开发者设定的动作。
下图中给出了达成跑鞋推荐目标的两个计划,其中计划1串联了
transform_occupation_to_price和rec_shoes_based_on_price这两个动作,而计划2则是串联了transform_occupation_to_type和 rec_shoes_based_on_type这两个动作。开发者可以为每个计划设定一个价值函数,DECAS则只需要选择价值最高的topN计划具体执行即可。当然,DECAS可能做得更复杂,比如依据用户反馈实时调整计划。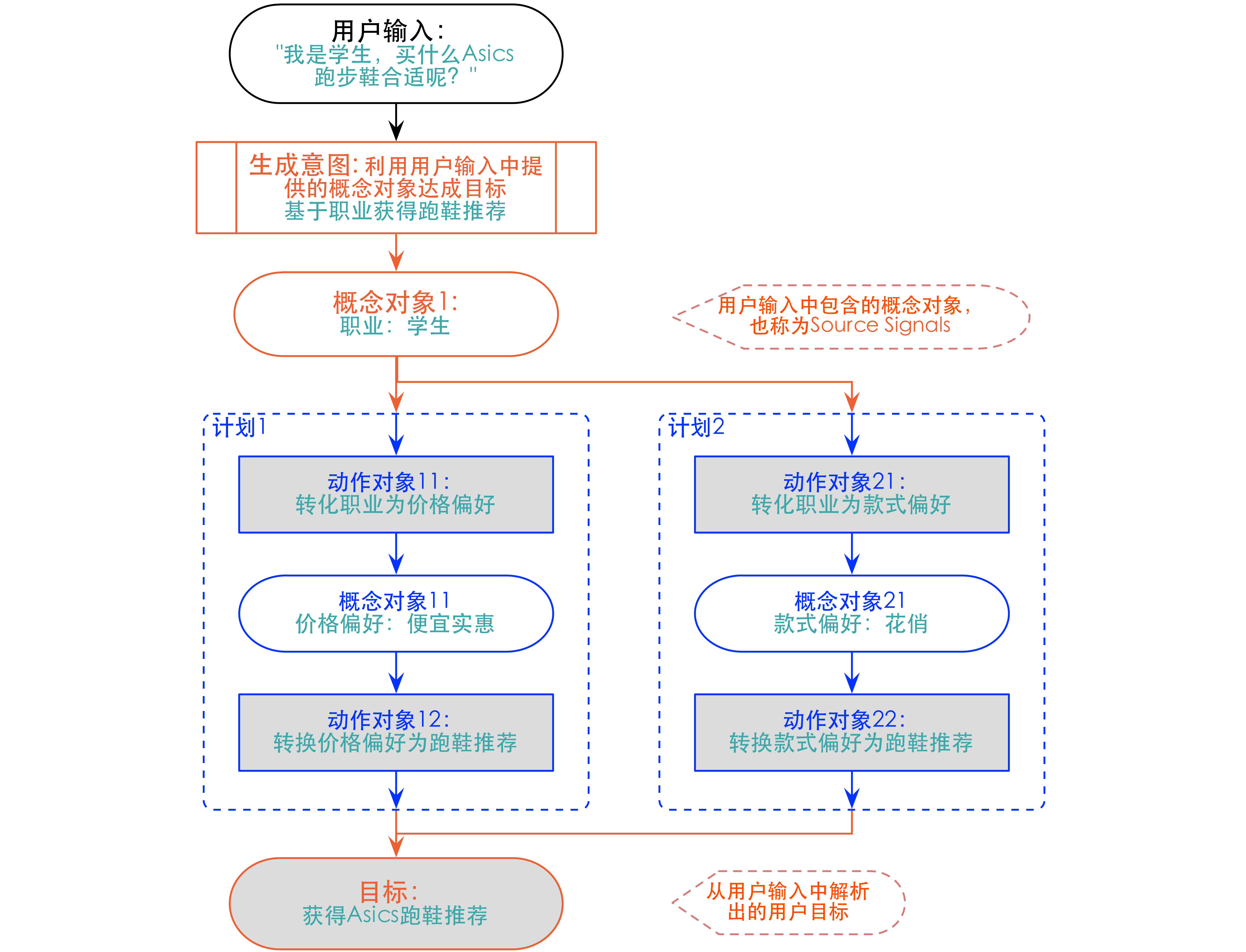
如果一个计划包含的动作所需的必须输入概念对象缺失,那么就需要与用户进行多次交互以收集缺失概念对象的值。
总结下,Viv 是以动作为核心的网络系统。 它首先让开发者定义对应领域的概念对象和动作对象,然后自动生成计划(网络图中找两个结点间的路径),利用用户输入中的概念对象完成用户的目标。相对于 Api.ai 和一个AI只能使用开发者设定的意图来完成已知的需求,Viv 在联合不同开发者定义的概念和动作对象后可以执行一些不在开发者设定范围内的意图。随着越来越多开发者接入 Viv,它能做的事会指数增长。Viv 在智能性/灵活性方面做得很好,但可控性会稍差,因为完成目标的计划都是由系统自动生成的,开发者难以介入。好的灵活性也会对开发者有更高的要求,开发者初期付出的管理成本可能不低。Viv 开发了很多辅助工具帮助开发者管理自己的应用,但这些工具能把开发者的管理成本降到什么程度目前尚不清楚。
关于 Viv 的更多细节,可见我之前的文章“Viv能搅动bot市场吗?”。
四、在路上的 Wit.ai
Wit.ai 在2014年就被 Facebook 收购了,今年上半年做了很大的改版。之前它的模式和一个AI类似,开发者可以手动设置状态以衔接不同的场景。
改版后,它取消了之前一个场景控制一轮对话的逻辑,变为以故事(Story)为对话单元。一个故事相当于完成用户某个需求的一条路径。所以一个故事通常包括多轮对话,或者说一个故事包括完成同一需求的多个(隐式)场景。故事是比场景更大的对话单元。下图给出了一个求约会故事的示例。
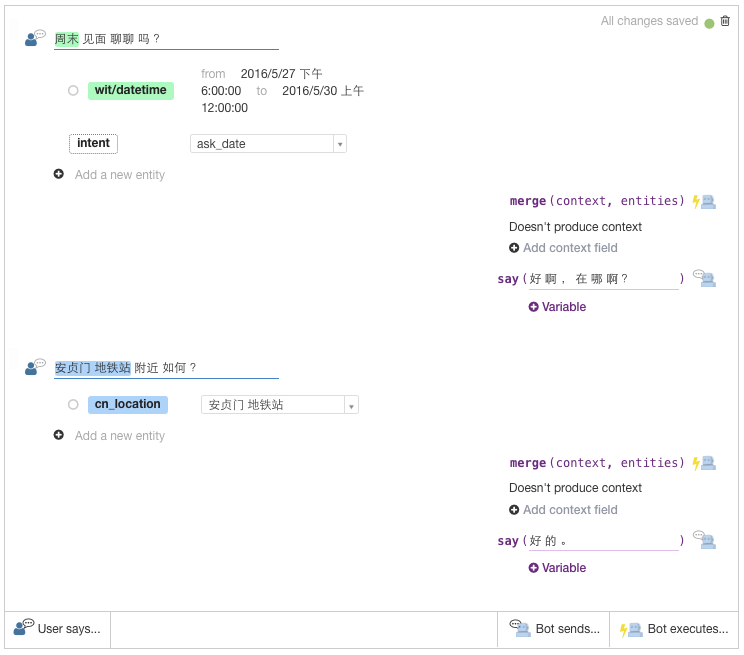
开发者可以为同一需求设定多个故事,代表完成此需求的多条路径,但也不需要为所有路径都创建一个故事。Wit.ai 可以使用已创建的故事来自动生成新的路径以完成某个需求。如果把故事中的一轮对话看成一个AI里的一个场景,那 wit.ai 就能自动衔接不同故事中的各种场景,以便创建完成需求的新故事或者新路径。类似的能力在 api.ai 和一个AI里更多是依靠开发者通过状态进行维护。
以故事为对话单元的好处是,开发者不再需要手动设置场景和状态了,系统可以通过学习来拆解已有故事并重新拼装成新的故事。在相同场景数的情况下wit.ai能回答的用户提问会比api.ai和一个AI多。但这种灵活性带来的坏处就是可控性下降。开发者很难控制某些路径不被自动创建,出现问题时开发者如何调整故事也变得很朦胧。而这些问题在 api.ai 和一个AI里是不存在的。
关于 wit.ai 的更多细节,可见我之前的文章 “低价制造chatbots的利器 Wit.ai”。
说了这么多,该说的终于说完了,简化一下就两条内容:
- 对话交互会在IoT万物互联时代爆发,这是追逐交互效率的必然结果。
- 不同的bot和bot平台的差别其实只是在可控性和智能性之间的权衡不同。技术的发展只是在不断拓展可控性和智能性的帕累托边界而已。我个人认为目前 api.ai 和一个AI的范式最适合国内小微企业。
<ins/>
- 作者:Breezedeus
- 链接:https://www.breezedeus.com/article/chatbot-tradeoff
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。









