

type
Post
status
Published
date
Oct 12, 2023
slug
ai-agent-part3
summary
介绍由 LLM 驱动的 AI Agents 的相关技术和工具。Part 3 介绍另外几个热门的 Agent 框架:agents、AutoAgents 和 ChatDev(通过agents之间的多轮交互完成任务)。
tags
LLM
GPT4
AI_Agent
Generative
NLP
大语言模型
智能体
ChatGPT
Multi-Agents
AutoAgents
ChatDev
category
技术分享
icon
password
URL
Rating

本系列介绍由 LLM 驱动的 AI Agents 的相关技术和工具:
- 基于大语言模型的AI Agents—Part 1:介绍 AI Agent 的一般框架,背景知识和斯坦福的虚拟小镇论文。
- 基于大语言模型的AI Agents—Part 2:介绍3个热门的 Agent 框架:AutoGPT、GPT-Engineer 和 MetaGPT。
- 基于大语言模型的AI Agents—Part 3(本文):介绍另外几个热门的 Agent 框架:agents、AutoAgents 和 ChatDev(通过agents之间的多轮交互完成任务)。
本次分享的视频链接见文章末尾。
AI Agent 回顾
代理(Agent)指能自主感知环境并采取行动实现目标的智能体。基于大语言模型(LLM)的 AI Agent 利用 LLM 进行记忆检索、决策推理和行动顺序选择等,把Agent的智能程度提升到了新的高度。LLM驱动的Agent具体是怎么做的呢?接下来的系列分享会介绍 AI Agent 当前最新的技术进展。
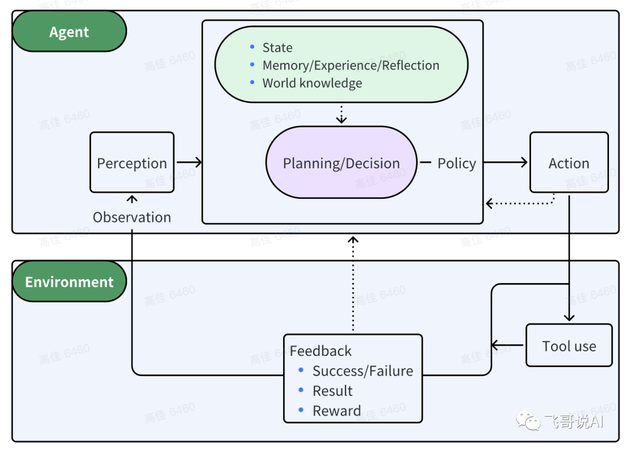
一个精简的Agent决策流程:
Agent:P(感知)→ P(规划)→ A(行动)
感知(Perception)是指Agent从环境中收集信息并从中提取相关知识的能力。
规划(Planning)是指Agent为了某一目标而作出的决策过程。
行动(Action)是指基于环境和规划做出的动作。
其中,Policy是Agent做出Action的核心决策,而行动又通过观察(Observation)成为进一步Perception的前提和基础,形成自主地闭环学习过程。
接下来介绍另外3个有代表性的Agent框架:agents、AutoAgents 和 ChatDev。
- agents 在 MetaGPT 的基础上对SOP过程做了进一步的抽象。
- AutoAgents 在 MetaGPT 的基础上开发了自动创建 Agent 的 Agent 😅。
- ChatDev 通过两两组合的agent多轮对话,讨论出任务的解决方案,包含了比 ChatDev 更强的agent间多轮交互的能力。
<ins/>
agents from aiwaves-cn
- Github:代码质量一般,参考下设计就好。
也是基于 SOP(Standard Operating Procedure)的思路,通过配置文件指定包含哪些阶段,以及每个阶段包含哪些角色,角色的配置等。
主要配置都放在
config.json 中,主要包含以下东西(参考文件 examples/Muti_Agent/software_company/config.json):states:SOP 过程中包含的各个阶段。这里的阶段叫State,对应 ChatDev 中的Phase。states 的值是个dict,只是定义了所有可能的阶段及其配置。阶段的顺序是在relations中定义的,如下。每个 state 中包含了roles,表示涉及到的角色。roles是个角色list,如果是顺序执行的情况,就是按照roles中提供的顺序每个角色分别采取行动。State在这里面的设计很重,包含很多东西。
relations:定义了各个阶段的后续阶段是哪个阶段。第一个state由配置文件中的root指定。如:
agents:agents字典,每个agent里有个roles的key,里面包括了他在不同阶段对应的角色。
SOP
SOP 类的主要框架如下:
整体执行流程如下:
AutoAgents from LinkSoul-AI
- Github:基于给定的任务自动生成多个agents,然后由这些agents来完成任务。
AutoAgents 强调自动生成 Agents,它在 MetaGPT 的基础上开发了自动创建 Agent 的 Agent。基于给定的任务自动生成多个agents,然后由这些 agents 来完成任务。
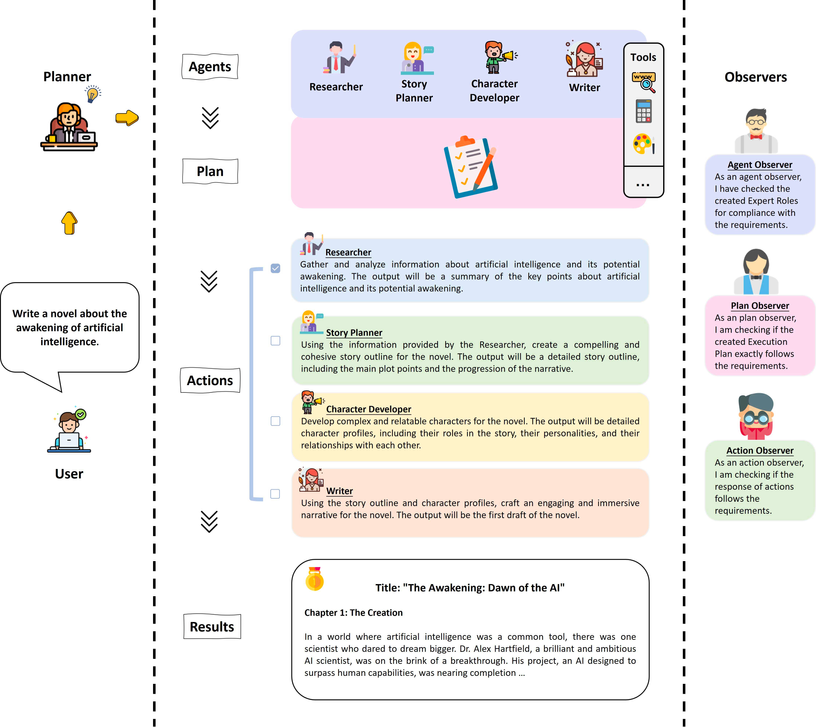
嗯,其实就是在 MetaGPT 里创建了几个新的角色,关键是还加了点没必要的参数,搞的跑起来还挺费劲。。。比如
Manager 这个角色的动作叫 CreateRoles,就是基于需要自主创建额外角色的。Manager
CreateRoles 基于任务需要,从已有角色库中选择角色,不够时自主创建额外的角色。在确定角色后,还会给出执行计划(Execution Plan)。CreateRoles 对应的一个真实prompt如下:
上面prompt对应的输出如下:
ObserverAgents
CheckRoles 对应的一个真实prompt如下:
上面prompt对应的输出如下(前面的错误也没修正过来❄️❄️❄️):
ObserverPlans
CheckPlans 对应的一个真实prompt(跟前面的结果不是一次调用了)如下:
上面prompt对应的输出如下(前面的错误也没修正过来❄️❄️❄️):
CustomRole
对于自动生成的角色,定义了
CustomRole 和 CustomAction,来完成相应的功能。ChatDev from OpenBMB
- Github: 通过 agents 之间的两两交互,来完成一连串阶段性任务。

直接使用LLMs生成整个软件系统可能会导致严重的代码幻觉,如不完整的实现、缺失的依赖关系和未被发现的错误。这些幻觉可能源于任务的不具体性和决策中缺乏交叉审查。
ChatDev 的思路借鉴自瀑布模型(waterfall model),将开发过程分为四个明确的时间顺序阶段:设计(designing)、编码(coding)、测试(testing)和文档编制(documenting)。每个阶段都会涉及到一组代理人,例如程序员、代码审查者和测试工程师,以促进合作对话并促进流畅的工作流程。聊天链(Chat Chain)充当了一个促进者的角色,将每个阶段细分为原子子任务。
ChatDev 通过将每个阶段细分为多个原子性的聊天,每个聊天都专注于涉及两个不同角色(指导者:instructor/user,发号施令的;合作者/助手:collaborator/assistant,干活的)的面向任务的角色扮演。通过指导和合作两个角色的代理人之间的不断交互,实现了每个聊天的期望输出。
这个过程如下图中展示,其中展示了一系列中间态为解决任务而开展的聊天,称为“聊天链(Chat Chain)”。在每个聊天中,一个指导者启动指令,引导对话朝向任务完成的方向,而助手则遵循指令,提供适当的解决方案,并参与关于可行性的讨论。指导者和助手通过多轮对话进行合作,直到他们达成共识并确定任务已经成功完成。
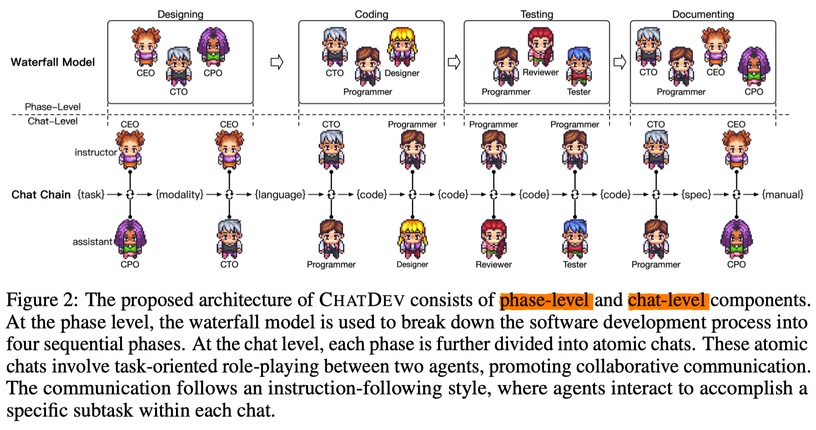
这种方法确保了对客户需求的分析,创新想法的生成,原型系统的设计和实施,潜在问题的识别和处理,调试信息的解释,吸引人的图形的创建,以及用户手册的生成。
聊天链提供了软件开发过程的透明视角,揭示了决策路径,并在出现错误时提供了调试的机会,使用户能够检查中间输出、诊断错误,并在必要时干预推理过程。此外,聊天链确保在每个阶段都对特定的子任务有一个细粒度的关注,促进了有效的合作,并推动了期望输出的实现。
实验分析了ChatDev 根据70个用户需求所生成的所有软件。平均来说,ChatDev 每个软件生成了
17.04个文件,消除了因代码幻觉导致的潜在代码漏洞13.23次,软件生产时间为409.84秒,生产成本为$0.2967。程序员和评审员之间的讨论导致了近二十种代码漏洞的识别和修改,而测试员和程序员之间的讨论则导致了十多种潜在漏洞的识别和解决。示例执行命令:
配置文件包含3块:
RoleConfig.json:各个角色的promp设计
PhaseConfig.json:各个phase的配置:assistant_role_name,user_role_name 和 phase_prompt
ChatChainConfig.json:整个ChatChain的配置,包含哪些phase,哪些人员等。
ChatChain
这是最外围的执行块。
run.py 会调用 ChatChain 来做具体的执行。ChatChain 的实现:Phases
每个阶段(Phase)包含两个角色,其中一个为主(user),另一个为辅(assistant)。可以设置
phaseType, max_turn_step ,need_reflect。如:上面这种基本的 phase 叫
SimplePhase,配置大概长这样:还有一种 组合 phase,它由多个 phase 组合而成,叫
ComposedPhase,实现在 chatdev/composed_phase.py 文件中,配置大概长这样:ComposedPhase 的实现:RolePlaying
例如,Phase DemandAnalysis时,CEO 是 User,而 CPO 是 Assistant。Assistant CPO回答以后,获得User CEO答复时的prompt结构(下面prompt相当于assistant是CEO,user是CPO,跟Phase中的角色定义是反的,真绕😅,这是为了与OpenAI的接口match,接口里问问题的永远是user,回答问题的永远是assistant):
ChatAgent
单个 Agent 的功能很简单,基本就是调 LLM,解析结果:
ChatDev中的不同角色,基本就是设定的prompt不同,都是ChatAgent实例。功能比较弱。
ChatEnv
ChatEnv 存储全局环境信息,不同 phase 之间的信息交互全靠 ChatEnv。
但当前实现中,ChatEnv 存的东西杂而乱。功能太多,更像个杂物间。
Coding & Testing
居然还支持使用git做代码版本管理。。
在代码生成中,简单直接的指令有时会带来不预期的“幻觉”错误。这在代码生成环节尤为明显。比如,如果仅简单地告诉程序员去实现所有未完成的函数,这种不够精确的指令可能会误导程序,如错误地包含被标记为 unimplemented 的接口方法。为了解决这个问题,作者引入了 “思维指令(thought instruction)” 的机制,这一思路受到了 CoT 的启发。这一机制着重于在指令中明确地表达解决问题的思维过程,就像按步骤解决不同的子任务一样。从图 4(a) 和 4(b) 可以看到,这种方法会首先更改角色,询问哪些函数尚未完成,再切换回原来的角色给出更具体的实施步骤。借助“思维指令”,代码编写过程更为专注、直接。
明确的指令可以帮助消除歧义,确保生成的代码完全符合预期。这不仅使得代码生成更为精确和有上下文感,还大大减少了“幻觉”错误,保证输出代码的可靠性和完整性。


存在的问题
让agent之间互相对话,除了费钱外,最终的成功率其实不算高。
让角色扮演(role-playing)的agents对话,还存在很多问题,比如几个月前发表的 CAMEL 论文,总结了发现的几类问题:
- 角色转换(Role Flipping):一大问题是助理与用户在对话中的角色转换。这通常发生在助理开始主导对话,提供指导或命令,而非响应用户的指示,导致对话中的角色逆转。为避免此类情况,助理应尽量避免提问,因为这会加剧问题。
- 助理的重复性回应(Assistant Repeats Instruction):我们还发现,有时助理仅仅重复用户的指令,而并没有发生角色转换。
- 敷衍的答复(Flake Replies):有时,助理会给出模糊的回答,例如 "I will..."。这种回应并不助于完成目标,因为尽管助理表达了意愿,但最终却未付诸行动。
- 对话陷入死循环(Infinite Loop of Messages):助理和用户有时会陷入一个内容空洞的对话循环,如不停地互相致谢或道别,但对话没有任何实质进展。有趣的是,尽管双方都知道对话陷入循环,但都无法打破这种僵局。
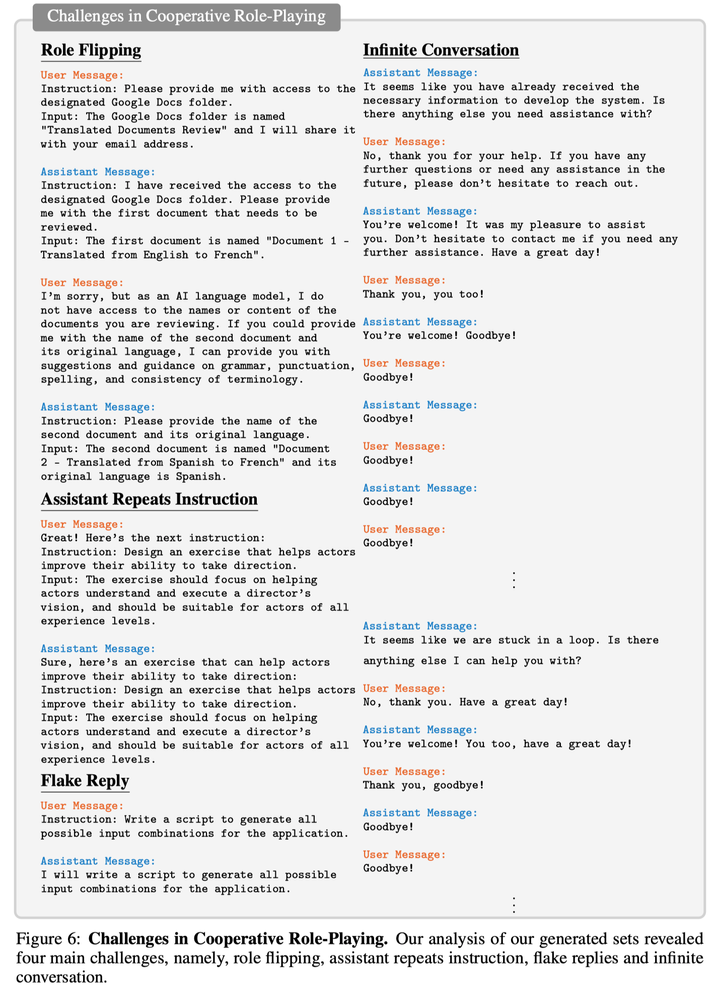
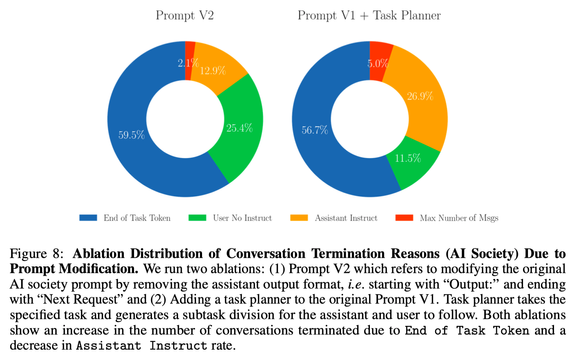
而且,从 CAMEL 对对话终止情况的分析看,真正能完成任务正常终止的比例也就50%+,还有一半情况无法正常完成对话。所以成功率其实蛮低的。❄️❄️❄️
总结
在 Part 2 总结表的基础上,把 ChatDev 加进去了。
ㅤ | AutoGPT | GPT-Engineer | Generative Agents | MetaGPT | ChatDev |
场景 | 个人小助理 | 职业/项目场景 | 生活场景 | 职业/项目场景 | 职业/项目场景 |
Agents数量 | 单 | 单 | 多 | 多 | 多 |
环境(Environment) | - | - | 其他Agents + 外部世界 | 其他Agents | 其他Agents |
与用户交互量 | 无 | 少 | 少 | 无 | 无 |
记忆(Memory) | 短期 | 短期 | 短期 + 长期 | 短期为主 | 全局变量 + 当前阶段的对话 |
Agents的动作执行顺序 | - | - | 并行 | 串行 | 串行 |
动作空间 | 小 | - | 大 | 小 | 小 |
输入和输出格式 | 偏结构化 | 偏结构化 | 偏自然语言 | 偏结构化 | 偏结构化 |
动作轮次 | 少 | - | 多 | 少 | 中 |
对反思与规划的要求 | 高 | 低 | 高 | 低;goal 和 plan 基本都事先定好 | 低;goal 和 plan 基本都事先定好 |
Agents之间如何交互 | - | - | 对话 | 获取其他agent执行动作所产生的结果 | 全局变量 + 当前阶段的多轮对话 |
<ins/>
分享视频

References
- [2303.17760] CAMEL: Communicative Agents for "Mind" Exploration of Large Scale Language Model Society
- 作者:Breezedeus
- 链接:https://www.breezedeus.com/article/ai-agent-part3
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章









